Pattern Sections
Pattern: Information
Holder Resource 
a.k.a. Generic Information Service, Data Entity Resource, Siloed/Isolated Data Holder
Context
A domain model, a conceptual entity-relationship diagram or another form of glossary of key application concepts and their interconnections have been specified. The model contains entities that have an identity and a life cycle as well as attributes; entities cross-reference each other.
From this analysis and design work, it has become apparent that structured data will have to be used in multiple places in the distributed system being designed; hence, these shared data structures have to be made accessible from multiple remote clients.
It is not possible or not easy to hide the shared data structured behind domain logic (i.e., processing-oriented actions such as business activities and commands); the application under construction does not have a workflow or other processing nature.
Problem
How can domain data be exposed in an API, but its implementation still be hidden? How can an API expose data entities so that API clients can access and/or modify these entities concurrently without compromising data integrity and quality?
Forces
Dealing with structured, possibly replicated data is one of the most challenging design issues in distributed systems; microservice APIs are no exception. Generally speaking, key factors that influence this general design issue are:
- Modeling approach and its impact on coupling
- Quality attribute conflicts and trade-offs such as concurrency, consistency; data quality and integrity; recoverability and availability; mutability and immutability
- Security
- Data freshness versus consistency
- Compliance with architectural design principles, such as loose coupling, logical and physical data independence, or microservices tenets such as independent deployability, e.g., when making architectural decisions about logical layers and physical tiers
The detailed forces that arise from these general concerns, as well as their relations, are discussed in the five concrete, specific types of information holders featured as separate patterns : Operational Data Holder, Master Data Holder, Reference Data Holder, Data Transfer Resource, and Link Lookup Resource.
A key decision is whether the endpoint should have activity (processing) semantics or data-oriented (entity state) semantics. This pattern explains how to emphasize data; its Processing Resource sibling focusses on action/activity orientation.
Pattern forces are explained in depth in the book.
Solution
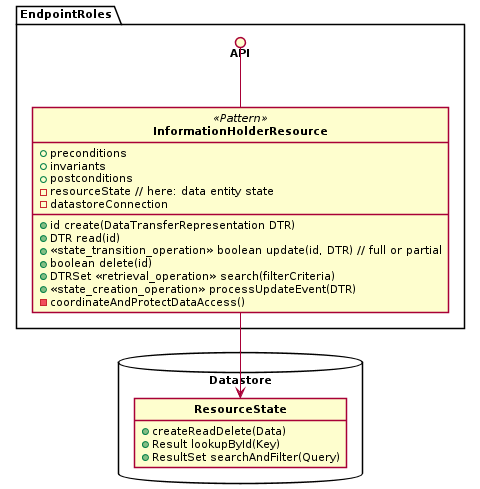
Add an Information Holder Resource endpoint to the API, representing a data-oriented entity. Expose create, read, update, delete, and search operations in this endpoint to access and manipulate this entity. In the API implementation, coordinate calls to these operations to protect the data entity.
Sketch
A solution sketch for this pattern from pre-book times is:
Example
The Customer Core
microservice in the Lakeside Mutual sample exposes master data. Its
semantics and its operations (e.g., changeAddress(...)) are
data- rather than action-oriented (the service is consumed by other
microservices that are
Processing
Resources):
@RestController
@RequestMapping("/customers")
public class CustomerInformationHolder {
@ApiOperation(
value = "Change a customer's address.")
@PutMapping(
value = "/{customerId}/address")
public ResponseEntity<AddressDto> changeAddress(
@ApiParam(
value = "the customer's unique id",
required = true)
@PathVariable CustomerId customerId,
@ApiParam(
value = "the customer's new address",
required = true)
@Valid @RequestBody AddressDto requestDto) {
[...]
}
@ApiOperation(
value = "Get a specific set of customers.")
@GetMapping(
value = "/{ids}")
public ResponseEntity<CustomersResponseDto>
getCustomer(
@ApiParam(
value = "a comma-separated list of customer ids",
required = true)
@PathVariable String ids,
@ApiParam(
value = "a comma-separated list of the fields
that should be included in the response",
required = false)
@RequestParam(
value = "fields", required = false,
defaultValue = "")
String fields) {
[...]
)
}Are you missing implementation hints? Our papers publications provide them (for selected patterns).
Consequences
The resolution of pattern forces and other consequences are discussed in our book.
Known Uses
Information Holders can be found in many public Web APIs and in middleware; they are seen less but do exist in business information systems:
- The Star Wars API positions itself as data-oriented; it provides six Information Holder Resources: films, people, planets, species, starships, and vehicles. Its operations include Retrieval Operations (HTTP GETs), supporting searches by name and, in some cases, other attributes such as starship model.
- Document-oriented databases such as CouchDB and MongoDB provide
native and direct access to the stored documents via
HTTP interfaces; hence, these documents qualify as instances of the
pattern. See for instance
GET /{db}/_all_docsin the CouchDB API. - Information management products deal with and expose Information Holder Resources by definition. Examples of such products include Master Data Management (MDM) and Product Information Management (PIM) systems; yet other systems deal with customer relationship data.
- Account information, billing statements, currency codes exposed in the APIs of cloud providers also qualify as known uses.
- Storage offerings such Dropbox, ownCloud and Amazon S3 provide abstractions such as file system space and key-value buckets; their APIs therefore also implement the Information Holder Resource pattern.
- A large data analytics solution currently being developed by a Swiss telecommunication service provider also uses this pattern to configure Hadoop jobs and supporting file systems.
- A Spring sample uses this pattern. It is criticized for its impact on coupling by M. Nygard in this blog post.
Pattern uses in enterprise and government SOAs include:
- The Dynamic Interface described in an OOPSLA 2004 experience report features a service that allows API clients to request an overview of selected bank customers and their financial transactions.
- Terravis Berli, Lübke,
and Möckli (2014) offers a
GetParcelIndexoperation, which can be called with different search parameters. The operation returns a list ofEGRIDs(i.e., electronic parcel identifiers), which uniquely identify parcels Swiss-wide and can be used to retrieve detailed parcel information from the federated land registry systems. - Usage scenarios such as open government data, partner information inventory, e-government data, and “show-only” data, e.g. mapping of partner id to user view in the real-estate process hub Terravis Lübke and Lessen (2016).
More Information
Related Patterns
This general Information Holder Resource pattern has several refinements that differ w.r.t. mutability, relationships, and instance lifetimes: Operational Data Holder, Master Data Holder, and Reference Data Holder.
The Link Lookup Resource pattern is another specialization; the lookup results may be Information Holder Resources. Finally, Data Transfer Resource holds temporary data owned by the clients.
The Processing Resource pattern represents complementary semantics and is an alternative to this pattern.
State Creation Operations and Retrieval Operations can typically be found in Information Holder Resources, modeling create, read, update, and delete semantics. Stateless Computation Functions and read-write State Transition Operations are less common, but also permitted.
Information Holder is a role stereotype in Responsibility-Driven Design (RDD) Wirfs-Brock and McKean (2002). Implementations of this pattern often can be seen as an API pendant to the Repository pattern in Domain-Driven Design (DDD) Evans (2003), Vernon (2013). Information Holder Resources are often implemented with one or more Entities from DDD, possibly grouped into an Aggregate. Note that no one-to-one correspondence between Information Holder Resource and Entities should be assumed because the primary job of the tactic DDD patterns is to organize the business logic layer of a system, not a (remote) Service Layer Fowler (2002).
Other Sources
Chapter 8 in “Process-Driven SOA” is devoted to business object integration and dealing with data Hentrich and Zdun (2011). “Data on the Outside versus Data on the Inside” by P. Helland explains the differences between data management on API and API implementation level Helland (2005); the article is commented in this blog post.
The online article “Understanding RPC Vs REST For HTTP APIs” talks about RPC vs. REST, but taking a closer look it actually (also) is about deciding between Information Holder Resources and Processing Resources.
Various consistency management patterns exist. We refer the reader to Fehling et al. (2014) which features patterns such as Strong Consistency and Eventual Consistency. A blog post from the Amazon Web Services CTO also covers this topic in depth Vogels (2009).